
Li(n)e
The last few months, I spent quite some time in one-on-one conversations on Twitter and Instagram with people looking for help on something they want to try with creative coding. Often, these conversations start with the same questions, what courses to follow, what books to read, what learning path to follow?
A knee jerk answer would be that there are plenty of resources out there, that we should do our own research, that Wikipedia, Google, and Stack Overflow hold all the answers. I’ve definitely been guilty of giving this reply. But generally, people aren’t asking what data structure to use, how to intersect two lines, or how to implement a particular algorithm. Those are the straightforward questions. They are asking on how to materialize an idea they have in their head. And that is the hard question of creative coding.
My interest in creative coding is mainly geometric. Points, lines, triangles interacting and intersecting, not as pixels, but as objects. Despite a science- and math-heavy background, and a reasonable computer science backpack, when I started creative coding in Processing I didn’t have the right tools to explore this.
Take the humble line.
Lines in Processing
Processing is an amazing coding tool. An IDE, a language, a community, it’s hard to overstate how important it has been for me. Of course, it’s not the only tool, not the only community, but it’s the one I’m most familiar with creative-coding-wise.
And like all those tools, it lies.
“I know what lines are,” it tells us, “and circles, boxes, triangles, and lots of other things.” We can go very far believing this. In fact, many of the books listed in this list devote chapters on line() and its counterparts.
In the reference page for line(), we see how Processing handles a line. Give it a pair of coordinates, and it draws the connecting line – or rather the line segment between the points.
|
1 2 3 4 5 6 7 8 |
void setup() { size(200, 200); } void draw() { background(250); line(20, 20, 180, 180); } |
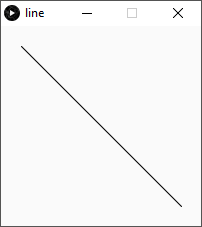
In Processing, a line is something we draw on the canvas. But the line itself is not an actual thing we can manipulate.
|
1 2 3 4 5 6 7 8 9 |
void setup() { size(200, 200); } void draw() { background(250); line(20, 20, 180, 180); line(180, 20, 20, 180); } |
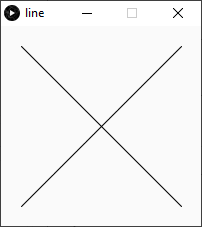
To illustrate, consider asking Processing where those two lines intersect. Not only is there no functionality to give us this, there isn’t even a way to refer to these two lines. line(20, 20, 180, 180) is “just” a command that draws pixels on the screen. line() is drawLine().
Lines in mathematics
In school, many of us are taught that a line is {y=mx+b}. In fact, this so-called slope-intercept form is the first mathematical definition in the Wikipedia entry for line. It makes sense. If we draw the {(x,y)} coordinates for a range of {x}, the result is a straight line after all. My guess is that for most of us this was all the exposure we got to lines in math, the graph of a linear function. (original image)
#/media/File:FuncionLineal01.svg){kind=link}
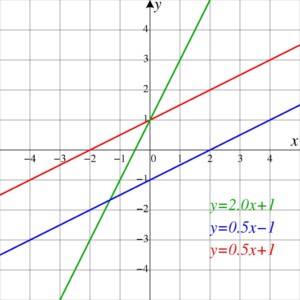
But when we want to use lines as base elements in creative coding, the linear function {y=mx+b} isn’t intuitive, isn’t what we’re looking for. The issue isn’t so much that the representation is different, two points vs. slope {m} and intercept {b}; or that a mathematical line is infinite and a Processing line is a segment; or that a vertical line can’t be expressed in the slope-intercept format. After all, we can convert between representations, the distinction between line and line segment can be considered academical, and exceptions can be handled accordingly.
A Line of thought
The largest issue is that there is a mismatch between our mental concept of a line, what Processing knows about lines, and what we were taught about the math of lines. Where we get lost most often isn’t in language syntax or in mathematics, which by themselves already are challenging, but in figuring out how to express ourselves in a way that the code works.
Let’s build a demo sketch to illustrate this. We want to create a bunch of random line segments and draw circles on every intersection. This will be the result: https://winterbloed.be/code/line.zip.
Personally, my first steps are always pencil on paper.
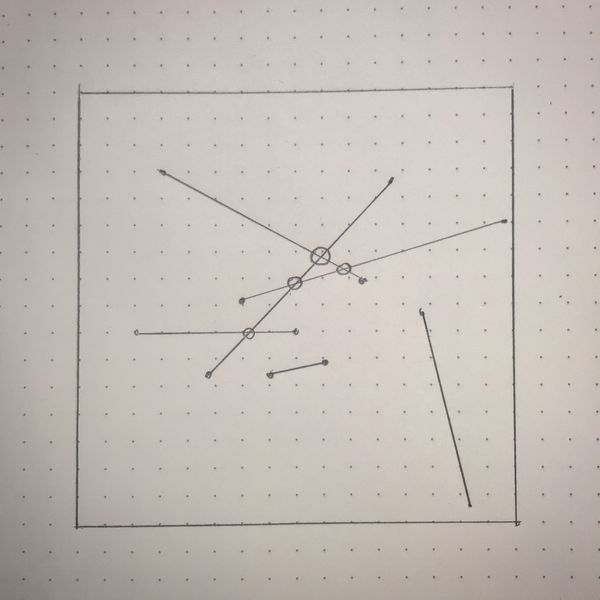
There’s nothing in this sketch that Processing can’t draw: points, lines, circles. But let’s not worry about the code yet. What are the essential elements in this idea? We have the square outline, some random line segments, and we have circles at their intersections. The outline will be our canvas and Processing takes care of that for us. We also know how to draw the lines and circles so we don’t need to figure that out.
What we first need, is something to refer to in the code when we talk about the line segments and intersections. Processing already knows points, it calls them PVector. But for this post, I’d like to take away the additional layer of knowing about its details, so we introduce our own basic Point class. For the moment, the only thing we need in a Point are its coordinates (x,y), we store these in two float properties.
|
1 2 3 4 5 6 7 |
class Point { float x, y; Point(float x, float y) { this.x=x; this.y=y; } } |
We’ll expand Processing’s knowledge further by introducing a class, a new concept, called Segment, the part of the line connecting two points. Again we need two properties, start and end, each a Point.
|
1 2 3 4 5 6 7 |
class Segment{ Point start,end; Segment(Point start, Point end){ this.start=start; this.end=end; } } |
Primitive and Object data types
Time for a detour, a long one, an illustration of how starting with creative coding throws us curve balls from every direction. Those two classes look very similar but are actually quite different. Consider this code snippet.
|
1 2 3 4 5 |
float x=10; float y=20; Point p=new Point(x,y); x=20; println(p.x); // p.x is still 10! |
We set up two variables x and y with a value, and create a new Point passing the variables as arguments. The constructor Point(x,y) tells the code to set the properties of the Point to the parameters we pass on. So far, so good. If we change our variable x, for example to create another Point, this has no effect on the created Point, its property x remains the original value.
This seems intuitive. Now, let’s look at this code snippet.
|
1 2 3 4 5 |
Point point1=new Point(10,20); Point point2=new Point(100,200); Segment seg=new Segment(point1, point2); point1.x=50; println(seg.start.x); // start.x has changed to 50! |
Again we set up two variables point1 and point2. We pass these to the Segment constructor to copy the variables to its properties, start and end. But when we change our variable point1 in some way, for example because we want to create a new segment, it also modifies the property start of our segment. That didn’t happen with float inside Point.
Let’s up the ante.
|
1 2 3 4 5 |
Point point1=new Point(10,20); Point point2=new Point(100,200); Segment seg=new Segment(point1, point2); point1= new Point(50,20); println(seg.start.x); // start.x is still 10! |
This looks very similar. But in this case changing point1 did not modify the property start of our segment.
Seemingly small changes in syntax lead to completely different behavior that can confuse us. This is both a blessing and a curse of coding. The code is doing exactly what we’re asking of it in all cases. But when we don’t master the language fully, which we don’t, sometimes we’re not asking the things we think we’re asking.
Behind the screens, different things happen when we pass a float as a argument to a function than when we do the same with something like Point. This has to do with data types. There’s a fundamental difference between float and Point.
Java has 8 Primitive data types: byte, short, int, long, float, double, char and boolean. In a way, a variable of one of these types is its value. An assignment like float x=y creates a new primitive float variable x, and sets it to the same value as y. Once this is done, there is no link between x and y. Changing one doesn’t affect the other.
Object data types are different. We recognize them because they are of a type which is not one of the 8 primitives, most often created with a constructor like Thingy thing=new Thingy(), although sometimes this is hidden behind the scenes. Rather than go with the formal computer science theory let me offer a visual analogy.
The warehouse
Object data types can be imagined as having two parts, their content and a label. I imagine them as boxes on a shelf. The content is everything inside the box and its label is a slip of paper telling us the name of the box, where to find it and what kind of box it is. With the right name, we can retrieve the label, find the box and examine its contents. Those contents can be properties (values, including (labels of) other Objects), or methods (instructions to do things).
In this analogy, the memory our code uses has two parts, a huge modular warehouse of shelves to store the boxes, and an inventory, a stack of labels on our desk. Each label holds the name, the directions to find a box, and what kind of content to expect. Every time we create a new Object, we create a label (“declaration”), we add a box to the warehouse (“instantiation”) and we fill the box with the needed content (“initialization”). The label goes on our desk. Its name is the name we give the variable. Going to a box to retrieve part of its contents is done with the accessor “.” segment.start can be read as: go to the box with label namesegment and access its start component.
Sometimes we want to store something so simple that we don’t need a box, we can note the value right there on the label, and store that in our stack. These are the primitive data types. There is no need for an accessor “.” since when we have the label, we already have the value.
So, what happens when we do something like float x=y. Well ,we first create a new label x and put it on our desk. Then we find label y and seeing it’s a Primitive, copy its value directly to the new label x. As a result, we have two labels with separate values. In the future, we can take label y, put in a new value, scratching out the old value. Label x isn’t affected.
Let’s follow this through when we do the same thing with an Object, like Point start=point1. First, we create a new label start and add it to our desk. Then we look up the label point1. Seeing that it’s an Object data type, it gives us the location of a box. If it fits the expected contents, a Point, we copy the directions on the new label start. However, we don’t create a new box or duplicate its contents. In the end, we have two separate labels, but they still point to the same box in our warehouse. No matter what label we use in the future to find the box, if we change anything to its contents, it is changed for all labels.
This way of working makes sense. There is no knowing in advance how big an Object is going to be, we can create anything after all. Copying a box and its content would potentially become very inefficient. For example, when passing a large Object as an argument to a function, in many cases it is unnecessary to create duplicates, we just want to examine the contents of the box. In Java/Processing, we pass Objects data types along to functions by their label, “by reference”, not by their contents, “by value”.
If we really want a separate box, then we need to explicitly create a new Object and copy the contents, not just the label. Point start=new Point(point1.x, point1.y) instead of Point start=point1. End result, two labels, two separate boxes.
This analogy also explains why in the last example, after assigning Point start=point1, doing point1=new Point(50,100) did not affect start. What we do there is create a new Object, a new box, and reuse an already existing label point1. That label now points to the new box. The label start hasn’t changed and is still pointing to the original box. Two labels, two boxes.
But wait, what happens if we do point1=new Point(10,100), immediately followed by point1=new Point(50,100), same as before but without assigning the Object to another variable like start. Doesn’t that leave the first box without a label? Why yes, yes it does. The directions to the original box are lost since we overwrote the label, and we have no other labels that hold the route to it. Without a label, we don’t even know what is supposed to be in the box, or how big it is. A box without label is taking up shelf space, but without any possibility of ever retrieving its content, effectively useless garbage.
That’s why in the background of a Java/Processing application there is a “garbage collector” running. This component is responsible for removing boxes without labels from the warehouse and freeing up shelf space. One of the telltale signs of this is when our application sometimes freezes for a few seconds after a certain time of running. There are ways of avoiding, or at least optimizing, this, but that’s a more advanced subject for another time.
Sometimes/often/all the time, we”ll create Objects that contain other Objects, like our Segment containing two Point instances. At first glance, we could imagine this as boxes within boxes. But that isn’t how the warehouse is organized. All boxes are stored separately on the shelves. What happens is that the box of the Segment has two labels inside, which can be used to retrieve its “subboxes”. When we create a Segment, we create one label on our desk, and in the Segment box we’ll find two more labels showing the way to its points. To access a property, we can chain the accessor: segment.start.x, go to the box with label segment, retrieve its content start, a label, follow it to its box, and finally retrieve the value x.
Because the boxes aren’t nested in each other, we can also imagine other organizations, like a Parent containing Child objects, that each in turn contain their Parent object, etc., without having to resort to Interstellar mind constructs 🙂 . In general, it’s better to think of “Object A referring to Object B” rather than “Object A containing Object B”.
As a last bit of analogy stretching, what happens when we create (“declare”) an Object type variable but don’t immediately give a value (“instantiate” and “initialize”), something like Point start? In that case, we can create the new label, put it on our desk, and already fill in what to expect, it’s going to be a Point. But there’s nothing to fill the box with yet, no content. It wouldn’t make sense to put an empty box in the warehouse, so for now we keep the label but have no corresponding box on the shelves. At a later point we can create the box with the existing label start=new Point(10,100), as long as the contents fit what we put on the label before. When we forget about this and try to retrieve the contents too early, we will discover that there are no directions on our label and the code returns a NullPointerException, or in our language “no directions on the label”.
That was a long detour, and thinking in terms of Primitive or Object data types isn’t something that is immediately intuitive. Hopefully, this – undoubtedly grossly oversimplified – analogy is useful. However, the detour is worth it, object oriented programming (OOP), even – or rather, especially – in its simplified Processing flavor is an extremely powerful tool that unlocks a lot of potential. We should not shy away from it, intimidated by the complexity of full-fledged computer science level OOP.
One way to protect us from OOP complexity and having to debug unintended changes to objects is by explicitly creating the properties anew. The following definition of the Segment class is safer, at the cost of having to store the contents of the start and end properties for every Segment. In terms of the analogy, each Segment box now refers to two Point boxes, uniquely assigned to it. The Segment label leads us to its box, and inside it are the two labels to the two Point boxes. Since the only place we keep the Point labels is inside the Segment box, there is no way to accidentally change the start and end points, unless we intentionally go through the segment, segment.start.x=50.
|
1 2 3 4 5 6 7 |
class Segment{ Point start,end; Segment(Point start, Point end){ this.start=new Point(start.x,start.y); this.end=new Point(end.x,end.y); } } |
Back on track
Let’s use our new classes and see how we would recreate the line() example from the reference.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
Segment segment; void setup() { size(200, 200); smooth(8); create(); } void create() { Point p1=new Point(20, 20); Point p2=new Point(width-20, height-20); segment=new Segment(p1, p2); } void draw() { background(255); segment.draw(); } class Point { float x, y; Point(float x, float y) { this.x=x; this.y=y; } } class Segment { Point start, end; Segment(Point start, Point end) { this.start=new Point(start.x, start.y); this.end=new Point(end.x, end.y); } void draw() { line(start.x, start.y, end.x, end.y); } } |
So far, our long walk hasn’t gained us anything, except maybe some befuddlement. The big conceptual difference is that in our code we do have a line segment to refer to. It’s also straightfoward to add more line segments.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
ArrayList<Segment> segments; int numSegments; void setup() { size(200, 200); smooth(8); numSegments=5; create(numSegments); } void create(int n) { segments=new ArrayList<Segment>(); Point p1, p2; for (int i=0; i<n; i++) { p1=new Point(random(20, width-20), random(20, height-20)); p2=new Point(random(20, width-20), random(20, height-20)); segments.add(new Segment(p1, p2)); } } void draw() { background(255); for (Segment segment : segments) { segment.draw(); } } class Point { ... } class Segment { ... } |
Checking our original sketch, we have our canvas, we have our lines. Now we need the intersections. First idea, let’s check line-line intersection on Wikipedia. Ok, that definitely holds the answer somewhere but it’s not a comfortable read. Stack Overflow? Chances are our first search results will not be very helpful either. Too many new things, notations, terms, and little indication where to focus. Unfortunately, there is no golden advice here, we start on a journey with an empty toolbox, and every task is hard.
Rather than be discouraged, we have to allow ourselves to be exposed to things we don’t get. That way we can pick up the vocabulary to ask the right questions, stumble on new sources, and more often than not get distracted by new areas of interest. Let’s pretend that in this case we ended up in a section of Paul Bourke’s website. Not an unlikely scenario, it’s one of the most useful and referenced websites with geometry tidbits and code. Well worth browsing.
Adding intersections
Somewhere down the page we find the section Intersection point of two line segments in 2 dimensions, exactly what we are looking for. It gives the intersection point (x,y) of two line segments, one going from (x_{1},y_{1}) to (x_{2},y_{2}), and the other going from (x_{3},y_{3}) to (x_{4},y_{4}). The solution is given as two equations, one for x and one for y.
x=x_{1}+u_a(x_{2}-x_{1})
y=y_{1}+u_a(y_{2}-y_{1})
Equations aren’t straightforward to read and will probably always remain something of an acquired taste. But let’s take them head-on. We’re looking for (x,y). These two equations tell us how to calculate x from x_{1},x_{2} and u_{a}, and similarly y from y_{1},y_{2} and u_{a}.
Some of these we know, x_{1},x_{2},y_{1} and y_{2} are properties of the segments. The only unknown is u_{a}. Luckily this is also given as part of the solution:
u_{a}=\frac{(x_{4}-x_{3})(y_{1}-y_{3})-(y_{4}-y_{3})(x_{1}-x_{3})} {(y_{4}-y_{3})(x_{2}-x_{1})-(x_{4}-x_{3})(y_{2}-y_{1})}
This equation isn’t really enlightening. It doesn’t tell us why this is a solution. But it tells us what steps to take to find a solution. Much like a recipe in fact: if we follow the steps, we end up with a cake. But why it ends up as a cake and not a lump of dry dough, the molecular gastronomy of the baking process, that’s something we can’t find in the recipe. It’s out there if we want to learn and some of us do. But it’s not needed to bake a cake. Another thing with equations is that the names used can be distracting, why u_{a}?
What’s wrong with plain old a? But we shouldn’t let that be a hangup. If celebrities are allowed to have weirdly named kids, surely maths and physics is allowed to have weirdly name variables – give us something.
Translating the formulae to Processing would look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Point intersection(Segment segment1, Segment segment2) { float x1=segment1.start.x; float y1=segment1.start.y; float x2=segment1.end.x; float y2=segment1.end.y; float x3=segment2.start.x; float y3=segment2.start.y; float x4=segment2.end.x; float y4=segment2.end.y; float ua=(x4-x3)*(y1-y3)-(y4-y3)*(x1-x3); float denominator=(y4-y3)*(x2-x1)-(x4-x3)*(y2-y1); ua/=denominator; float xi=x1+ua*(x2-x1); float yi=y1+ua*(y2-y1); return new Point(xi, yi); } |
This is a one-on-one correspondence to the mathematical equations. In fact, I like to explicitly define the variables even though it’s not strictly needed. It makes the inevitable debugging easier.
There’s a snag. If we use this function in our code, occasionally it will cause it to crash, ArithmeticException: / by zero. This happens when denominator is zero. If we would do a rigorous analysis – or read Paul Bourke’s notes – we can prove that this happens when the two line segments are parallel. Parallel line segments either overlap or don’t intersect. Since this is our sketch, we can decide what to do in edge cases like this, we decide to ignore overlapping segments.
A little addition takes care of this by returning null instead of a Point when denominator is very close to zero, i.e. segments very close to being parallel. The reason we don’t take exactly zero is that this intersection test becomes rather imprecise for nearly parallel lines. Dividing by a very small number is like multiplying with a very large number and round-off errors become too large for the result to be useful.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
Point intersection(Segment segment1, Segment segment2) { float x1=segment1.start.x; float y1=segment1.start.y; float x2=segment1.end.x; float y2=segment1.end.y; float x3=segment2.start.x; float y3=segment2.start.y; float x4=segment2.end.x; float y4=segment2.end.y; float ua=(x4-x3)*(y1-y3)-(y4-y3)*(x1-x3); float denominator=(y4-y3)*(x2-x1)-(x4-x3)*(y2-y1); if(abs(denominator)<0.0001) return null; ua/=denominator; float xi=x1+ua*(x2-x1); float yi=y1+ua*(y2-y1); return new Point(xi, yi); } |
Let’s say we have 5 segments. How would we go about checking the intersections manually? We’d start with the first segment, check if it intersects the second, the third,… up to the fifth. Then we take the second segment. There is no need to check intersection with the first segment because we already did that. But we need to check the third, fourth and fifth. And so on. Another thing is that we don’t check the segments intersecting with themselves. Maybe our first code would be something like:
|
1 2 3 4 5 |
for(int i=0;i<n;i++){ for(int j=0;j<n;j++){ ... } } |
But we do too much. Not only do we unnecessarily check every segment with itself, we also check every segment pair twice. When we start with the second segment, we check intersection with the first one again. We would end up with every intersection point counted twice. The following nested loops take care of that and it is a useful construct when having to check unique pairs, like distances between points.
|
1 2 3 4 5 |
for(int i=0;i<n;i++){ for(int j=i+1;j<n;j++){ ... } } |
We introduce a new function to find all intersections.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
void findIntersections(){ Segment segment1, segment2; Point intersection; intersections=new ArrayList<Point>(); for(int i=0;i<numSegments;i++){ segment1=segments.get(i); for(int j=i+1;j<numSegments;j++){ segment2=segments.get(j); intersection=intersection(segment1,segment2); if(intersection!=null) intersections.add(intersection); } } } |
Putting everything together
Assembling all pieces so far, we get this.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
ArrayList<Segment> segments; ArrayList<Point> intersections; int numSegments; void setup() { size(800, 800,P3D); smooth(16); numSegments=16; create(numSegments); findIntersections(); } void create(int n) { segments=new ArrayList<Segment>(); Point p1, p2; for (int i=0; i<n; i++) { p1=new Point(random(20, width-20), random(20, height-20)); p2=new Point(random(20, width-20), random(20, height-20)); segments.add(new Segment(p1, p2)); } } void findIntersections(){ Segment segment1, segment2; Point intersection; intersections=new ArrayList<Point>(); for(int i=0;i<numSegments;i++){ segment1=segments.get(i); for(int j=i+1;j<numSegments;j++){ segment2=segments.get(j); intersection=intersection(segment1,segment2); if(intersection!=null) intersections.add(intersection); } } } void draw() { background(255); for (Segment segment : segments) { segment.draw(); } stroke(255,0,0); for(Point intersection : intersections){ ellipse(intersection.x,intersection.y,10,10); } } Point intersection(Segment segment1, Segment segment2) { float x1=segment1.start.x; float y1=segment1.start.y; float x2=segment1.end.x; float y2=segment1.end.y; float x3=segment2.start.x; float y3=segment2.start.y; float x4=segment2.end.x; float y4=segment2.end.y; float ua=(x4-x3)*(y1-y3)-(y4-y3)*(x1-x3); float denominator=(y4-y3)*(x2-x1)-(x4-x3)*(y2-y1); if(abs(denominator)<0.0001) return null; ua/=denominator; float xi=x1+ua*(x2-x1); float yi=y1+ua*(y2-y1); return new Point(xi, yi); } class Point { float x, y; Point(float x, float y) { this.x=x; this.y=y; } } class Segment { Point start, end; Segment(Point start, Point end) { this.start=new Point(start.x, start.y); this.end=new Point(end.x, end.y); } void draw() { fill(0); stroke(0); line(start.x, start.y, end.x, end.y); ellipse(start.x, start.y,3,3); ellipse(end.x, end.y,3,3); } } |

Nice! But… not exactly what we were going for. There are intersections outside of the segments. That can’t be right? Turns out, language tripped us up.
What we did so far was look for line-line intersections, but a line in the mathematical definition of the term is infinite. It makes sense that we get intersections outside of the finite segments. What we really wanted is segment-segment intersection. This is what Paul Bourke has to say in the notes to the equations: “The equations apply to lines, if the intersection of line segments is required then it is only necessary to test if u_{a} and u_{b} lie between 0 and 1. Whichever one lies within that range then the corresponding line segment contains the intersection point. If both lie within the range of 0 to 1 then the intersection point is within both line segments. “
So let’s do that.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
Point intersection(Segment segment1, Segment segment2) { float x1=segment1.start.x; float y1=segment1.start.y; float x2=segment1.end.x; float y2=segment1.end.y; float x3=segment2.start.x; float y3=segment2.start.y; float x4=segment2.end.x; float y4=segment2.end.y; float ua=(x4-x3)*(y1-y3)-(y4-y3)*(x1-x3); float denominator=(y4-y3)*(x2-x1)-(x4-x3)*(y2-y1); if(abs(denominator)<0.0001) return null; ua/=denominator; if(ua<0 || ua>1){ return null; } float ub=(x2-x1)*(y1-y3)-(y2-y1)*(x1-x3); ub/=denominator; if(ub<0 || ub>1){ return null; } float xi=x1+ua*(x2-x1); float yi=y1+ua*(y2-y1); return new Point(xi, yi); } |
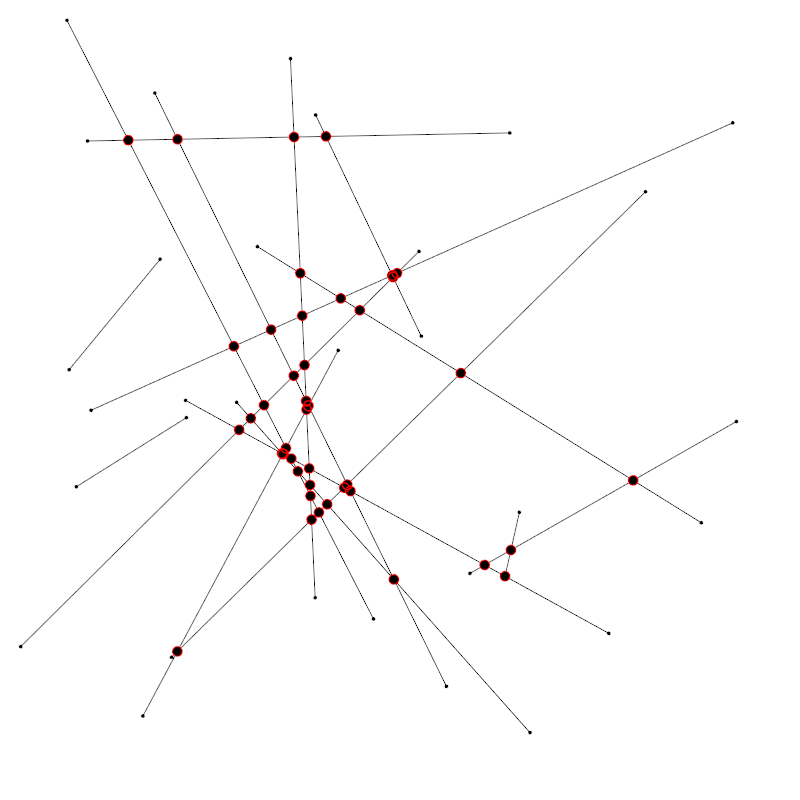
There we have it. One geometric idea implemented in Processing. To arrive there we needed to tackle some issues and subtleties, tiny parts of the vast knowledge areas of mathematics, computer science,… Maybe the most important skills in creative coding are not coding or math, but the abilities to overcome what we don’t know yet, to realize we’re not getting it exactly right, and to accept it *is* enough for now.
Processing code for this ramble: https://winterbloed.be/code/line.zip